Die Double-Dabble -Technik konvertiert Binärdaten durch wiederholtes Verschieben in BCD. Jede Wiederholung halbiert die verbleibende Binärzahl und verdoppelt die BCD-Zahl. Nachdem der vollständige Binärwert verschoben wurde, wird das Ergebnis erhalten. Nach jeder Verschiebung wird eine Korrektur auf jede 4-Bit-BCD-Spalte angewendet (oder auf solche mit mehr als 3 Bits, die um diesen Punkt verschoben wurden). Diese Korrektur sucht nach Ziffern, bei denen die Dezimalzahl 9 -> 10 bei der nächsten Schicht überläuft, und korrigiert das Ergebnis durch Hinzufügen von drei .
Warum drei? BCD-Ziffern im Bereich von null bis vier (0,1,2,4) verdoppeln sich nach der Verschiebung auf natürliche Weise auf 0,2,4,8. Wenn Sie 5 b 0101 untersuchen, wird dies zu b 1010 (0xA) verschoben, was keine BCD-Ziffer ist. 5 wird daher auf (3 + 5) korrigiert, dh b 1000 (0x8), was sich während der Verschiebung auf 16 Dezimalstellen (0x10) verdoppelt, was einen Übertrag von 1 zur nächsten Ziffer und der erwarteten Null darstellt.
Implementierungen wiederholen diesen Vorgang entweder zeitlich synchron unter Verwendung eines Schieberegisters und von 'n' Zyklen für einen n-Bit-Eingang oder im Raum, indem sie die Logikschaltungen für die Korrektur platzieren, die sich gegenseitig speisen und die Verschiebung durchführen mit Verkabelung. Es gibt einen Übertragspfad durch jede Ziffer, und die Übertragslogik ist nicht für die FPGA-Übertragungskettenlogik (binär) geeignet, sodass die Raumimplementierung im Allgemeinen inakzeptable Zeitsteuerungsergebnisse für große Eingaben liefert. Ein typischer technischer Kompromiss.
Für eine parallele (asynchrone) Konvertierung
Für enge Werte wie Ihren Dr. Auf der Website von John Loomis finden Sie eine Anleitung zur Logikstruktur, die für die Implementierung in Hardware erforderlich ist. Moderne umprogrammierbare Logik kann nach aggressiver Synthese eine Breite von 8 Bit bis zu 100 MHz erreichen. Das Modul add3 nimmt eine 4-Bit-Eingabe und gibt sie wörtlich aus, oder wenn mehr als vier, fügt es drei hinzu:
Modul add3 (in, out); input [ 3: 0] in; Ausgabe [3: 0] out; reg [3: 0] out; immer @ (in) case (in) 4'b0000: out < = 4'b0000; // 0 -> 0 4'b0001: out < = 4'b0001;
4'b0010: out < = 4'b0010; 4'b0011: out < = 4'b0011; 4'b0100: out < = 4'b0100; // 4 -> 4 4'b0101: out < = 4'b1000; // 5 -> 8 4'b0110: out < = 4'b1001; 4'b0111: out < = 4'b1010; 4'b1000: out < = 4'b1011; 4'b1001: out < = 4'b1100; // 9 -> 12 default: out < = 4'b0000; endcaseendmodule
Die Kombination dieser Module ergibt die Ausgabe. 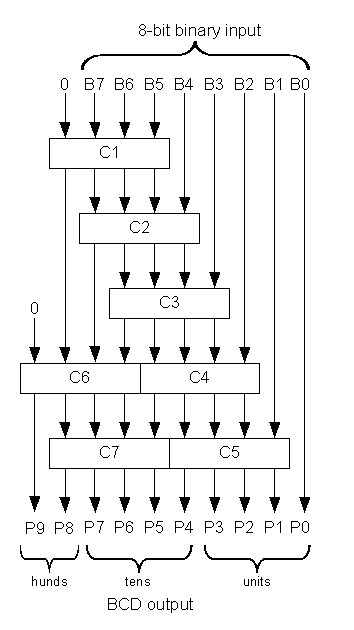
Für eine sequentielle Variante (mit mehreren Zyklen, Pipeline)
Für Wide signalisiert eine serielle Technik, die in Xlinx App Note "XAPP 029" beschrieben ist und 1 Bit pro Zyklus ausführt, wahrscheinlich mit 300 MHz +.
Wenn jemand eine gute Hybridtechnik kennt, wäre ich interessiert es zu wissen. Ich habe beide in Verilog mit Prüfständen in meiner verilog-utils -Sammlung modelliert.