Ihre Versuche
Per Definition verursachen Sie eine Sättigung, wenn Sie Werte in Ihrem Code "hart begrenzen". Es ist vielleicht keine Sättigung im Sinne eines Überlaufens Ihres Short, aber Sie verzerren die Welle immer noch, wenn sie einen bestimmten Punkt überschreitet. Hier ist ein Beispiel:
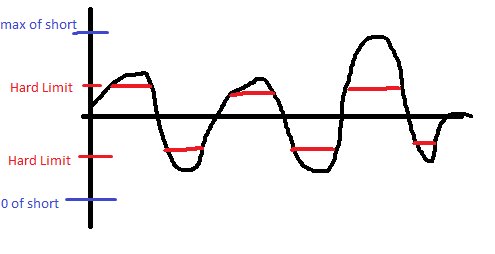
Mir ist klar, dass Sie im unteren Bereich wahrscheinlich nicht stark eingeschränkt sind, aber ich hatte es bereits gezeichnet, bevor ich das erkannte.
Mit anderen Worten, die Hard-Limiting-Methode funktioniert nicht.
Bei Ihrem zweiten Ansatz veranlassen Sie diese Methode, das zu tun, was einige Audio-Leute tatsächlich absichtlich tun. Sie verursachen, dass jedes Bild so laut wie möglich ist. Diese Methode kann in Ordnung sein, wenn Sie die richtige Skalierung erhalten und Ihre Musik die ganze Zeit laut klingt, aber für die meisten Menschen ist sie nicht besonders gut.
Eine Lösung
Wenn Sie den maximal möglichen effektiven Gewinn kennen, den Ihr System erzielen kann, können Sie Ihre Eingabe durch so viel teilen. Um herauszufinden, was dies sein würde, müssen Sie Ihren Code durchgehen und bestimmen, was die maximale Eingabe ist, ihm eine Verstärkung von x geben, herausfinden, was die maximale Ausgabe in Bezug auf x ist, und dann bestimmen, in welcher x sein soll um nie zu sättigen. Sie würden diese Verstärkung auf Ihr eingehendes Audiosignal anwenden, bevor Sie etwas anderes tun.
Diese Lösung ist in Ordnung, aber nicht für alle geeignet, da Ihr Dynamikbereich ein wenig beeinträchtigt werden kann, da Sie dies normalerweise nicht tun läuft die ganze Zeit mit maximaler Eingabe.
Die andere Lösung besteht darin, eine automatische Verstärkung durchzuführen. Diese Methode ähnelt der vorherigen Methode, aber Ihre Verstärkung ändert sich im Laufe der Zeit. Dazu können Sie Ihren Maximalwert für jeden Frame Ihrer Eingabe überprüfen. Sie werden diese Zahl speichern und einen einfachen Tiefpassfilter auf Ihre Maximalwerte setzen und entscheiden, welche Verstärkung mit diesem Wert angewendet werden soll.
Hier ist ein Beispiel dafür, wie Ihre Verstärkung gegenüber dem Eingangsvolumen aussehen würde:
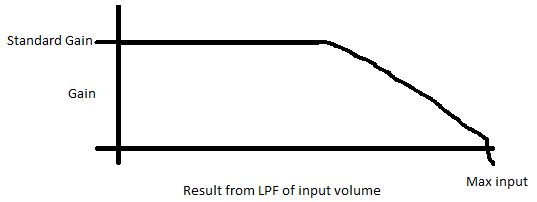
Diese Art von System führt dazu, dass der Großteil Ihres Audios einen hohen Dynamikbereich aufweist. Wenn Sie sich jedoch der maximalen Lautstärke nähern, können Sie die Verstärkung langsam reduzieren.
Daten Analyse
Wenn Sie herausfinden möchten, welche Art von Werten Ihr System tatsächlich in Echtzeit erhält, benötigen Sie eine Art Debugging-Ausgabe. Diese Ausgabe ändert sich je nachdem, auf welcher Plattform Sie ausgeführt werden. Hier finden Sie jedoch einen allgemeinen Überblick darüber, was Sie tun würden. Wenn Sie sich in einer eingebetteten Umgebung befinden, benötigen Sie eine serielle Ausgabe. Was Sie tun werden, ist in bestimmten Phasen Ihrer Code-Ausgabe in eine Datei oder einen Bildschirm oder etwas, von dem Sie die Daten abrufen können. Nehmen Sie diese Daten und geben Sie sie in Excel von Matlab ein und zeichnen Sie sie alle gegen die Zeit auf. Sie werden wahrscheinlich sehr leicht erkennen können, wo etwas schief geht.
Sehr einfache Methode
Sättigen Sie Ihr Double? Es klingt nicht so, stattdessen klingt es so, als ob Sie gesättigt sind, wenn Sie zu einem Kurzschluss wechseln. Eine sehr einfache und "schmutzige" Methode besteht darin, das Maximum Ihres Double zu konvertieren (dieser Wert ist je nach Plattform unterschiedlich) und diesen zu skalieren, um den Maximalwert Ihres Short zu erreichen. Dies garantiert, dass Sie Ihren Short auch nicht überlaufen, vorausgesetzt, Sie überlaufen Ihr Double nicht. Dies führt höchstwahrscheinlich dazu, dass Ihre Ausgabe viel weicher ist als Ihre Eingabe. Sie müssen nur herumspielen und einige der oben beschriebenen Datenanalysen verwenden, damit das System perfekt für Sie funktioniert.
Fortgeschrittenere Methoden, die wahrscheinlich nicht auf Sie zutreffen stark>
In der digitalen Welt gibt es einen Kompromiss zwischen Auflösung und Dynamikbereich. Dies bedeutet, dass Sie eine feste Anzahl von Bits für Ihr Audio haben. Wenn Sie den Bereich verringern, in dem sich Ihr Audio befinden kann, erhöhen Sie die Bits pro Bereich, den Sie haben. Wenn Sie im Sinne von Volt darüber nachdenken und über einen 0-5-V-Eingang und einen 10-Bit-ADC verfügen, müssen Sie einem 5-V-Bereich 10 Bit geben. Dies erfolgt normalerweise linear. Also 0b0000000000 = 0 V, 0b1111111111 = 5 V und Sie weisen den Bits die Spannungen linear zu. In der Realität ist dies bei Audio nicht immer eine gute Verwendung Ihrer Bits.
Im Fall von Sprache sehen Ihre Spannungen im Vergleich zur Wahrscheinlichkeit dieser Spannungen ungefähr so aus:
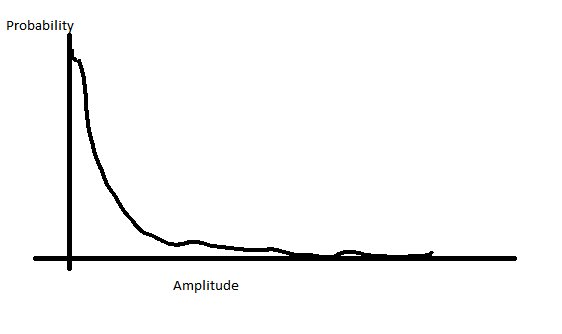
Dies bedeutet, dass Sie viel mehr von Ihrer Stimme in der niedrigeren Amplitude und nur eine kleine Menge in der hohen Menge haben. Anstatt Ihre Bits direkt zuzuweisen, können Sie Ihre Bits neu zuordnen, um mehr Schritte im unteren Amplitudenbereich und damit weniger im oberen Amplitudenbereich zu haben. Dies gibt Ihnen das Beste aus beiden Welten, eine Auflösung, bei der sich der größte Teil Ihres Audios befindet, aber begrenzen Sie Ihre Sättigung, indem Sie Ihren Dynamikbereich erhöhen.
Diese Neuzuordnung ändert nun die Funktionsweise Ihrer Filter und muss dies wahrscheinlich tun Überarbeiten Sie Ihre Filter, aber deshalb finden Sie dies im Abschnitt "Erweitert". Da Sie Ihre Arbeit mit einem Double erledigen und dann in einen Short umwandeln, muss Ihr Short wahrscheinlich sowieso linear sein. Ihr Double bietet Ihnen bereits viel mehr Präzision als Ihr Short, sodass diese Methode wahrscheinlich nicht erforderlich ist.